Jiageng Mao
Jiageng is a final-year PhD candidate at the University of Southern California, advised by Prof. Yue Wang. His
research centers on physical AI. His goal is to bring AI to the real world by developing algorithms across
robotics, computer vision, and language models. He is particularly interested in training large
vision-language(-action) models and world(-action) models. He has held positions at NVIDIA Research
and Google DeepMind. His research is supported by a Qualcomm Innovation Fellowship and an NVIDIA
Graduate Fellowship.
X (Twitter)
G.
Scholar
LinkedIn
Github
Curriculum Vitae
jiagengm at usc dot edu

2026
Introducing Psi-0, our first foundation model for universal humanoid loco-manipulation.2025
Awarded NVIDIA Graduate Fellowship.2025
RoLA is accepted to CoRL 2025 and presented as an oral presentation at ICCV Digital Twins workshop.2025
UH-1 is accepted to HUMANOIDS 2025 as an oral presentation.2025
Working at Google DeepMind on world modeling for robotics.2025
PhysBench is accepted to ICLR 2025 as an oral presentation (Top 1.8%).2024
Awarded Qualcomm Innovation Fellowship.2024
RAM is accepted to CoRL 2024 as an oral presentation (Top 5%).2024
Agent-Driver is accepted to COLM 2024 with Top 1% reviewer ratings.2024
Worked at NVIDIA Research on 4D scene generation.Ψ₀: An Open Foundation Model Towards Universal Humanoid Loco-Manipulation
Songlin Wei*, Hongyi Jing*, Boqian Li*, Zhenyu Zhao*, Jiageng Mao, Zhenhao Ni, Sicheng He, Jie Liu,
Xiawei
Liu, Kaidi Kang, Sheng Zang, Weiduo Yuan, Marco Pavone, Di Huang, Yue Wang.
In submission, 2026.
Project Page •
Code •
Model
Humanoid Everyday: A Comprehensive Robotic Dataset for Open-World Humanoid Manipulation
Zhenyu Zhao*, Hongyi Jing*, Xiawei Liu, Jiageng Mao†, Abha Jha, Hanwen Yang, Rong Xue,
Sergey Zakharov, Vitor Guizilini, Yue Wang†.
International Conference on Robotics and Automation (ICRA), 2026.
Project Page •
Code •
Dataset
Robot Learning from a Physical World Model
Jiageng Mao, Sicheng He, Hao-Ning Wu, Yang You, Shuyang Sun, Zhicheng Wang, Yanan Bao, Huizhong
Chen, Leonidas Guibas, Vitor Guizilini, Howard Zhou, Yue Wang.
International Conference on Robotics and Automation (ICRA), 2026.
Project Page •
Demo
Robot Learning from Any Images
Jiageng Mao*, Siheng Zhao*, Wei Chow, Zeyu Shangguan, Tianheng Shi, Rong Xue, Yuxi Zheng, Yijia
Weng, Yang You, Daniel Seita, Leonidas Guibas, Sergey Zakharov, Vitor Guizilini, Yue Wang.
Conference on Robot Learning (CoRL), 2025.
★ Oral Presentation at ICCV Digital Twins Workshop★
Project Page •
Code
Universal Humanoid Robot Pose Learning from Internet Human Videos
Jiageng Mao*, Siheng Zhao*, Siqi Song*, Tianheng Shi, Junjie Ye, Mingtong Zhang, Haoran Geng,
Jitendra Malik, Vitor Guizilini, Yue Wang.
International Conference on Humanoid Robots (HUMANOIDS), 2025.
★ Oral Presentation ★
Project Page •
Code •
Dataset
Seeing the Wind from a Falling Leaf
Zhiyuan Gao*, Jiageng Mao*, Hong-Xing (Koven) Yu, Haozhe Lou, Emily Yue-Ting Jia, Jernej Barbic,
Jiajun Wu, Yue Wang.
Neural Information Processing Systems (NeurIPS), 2025.
Project Page
PhysBench: Benchmarking and Enhancing Vision-Language Models for Physical World Understanding
Wei Chow*, Jiageng Mao*, Boyi Li, Daniel Seita, Vitor Guizilini, Yue Wang.
International Conference on Learning Representations (ICLR), 2025.
★ Oral Presentation (Top 1.8%) ★
Project Page •
Code •
Dataset
DreamDrive: Generative 4D Scene Modeling from Street View Images
Jiageng Mao, Boyi Li, Boris Ivanovic, Yuxiao Chen, Yan Wang, Yurong You, Chaowei Xiao, Danfei Xu,
Marco Pavone, Yue Wang.
International Conference on Robotics and Automation (ICRA), 2025.
★ Featured in NVIDIA's keynote talk at CES 2025. ★
CES-Video •
Project Page •
Code
A Language Agent for Autonomous Driving
Jiageng Mao*, Junjie Ye*, Yuxi Qian, Marco Pavone, Yue Wang.
Conference on Language Modeling (COLM), 2024.
★ Top 1% reviewer ratings (Top 10 out of 1036 submissions). ★
Project Page •
Code
RAM: Retrieval-Based Affordance Transfer for Generalizable Zero-Shot Robotic Manipulation
Yuxuan Kuang*, Junjie Ye*, Haoran Geng*, Jiageng Mao, Congyue Deng, Leonidas Guibas, He Wang, Yue
Wang.
Conference on Robot Learning (CORL), 2024.
★ Oral presentation (Top 5%). ★
Project Page •
Code
Driving Everywhere with Large Language Model Policy Adaptation
Boyi Li, Yue Wang, Jiageng Mao, Boris Ivanovic, Sushant Veer, Karen Leung, Marco Pavone.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024.
★ Featured at NVIDIA GTC 2024 & NVIDIA Drive Labs. ★
GTC-Video •
DriveLab-Video •
Project Page
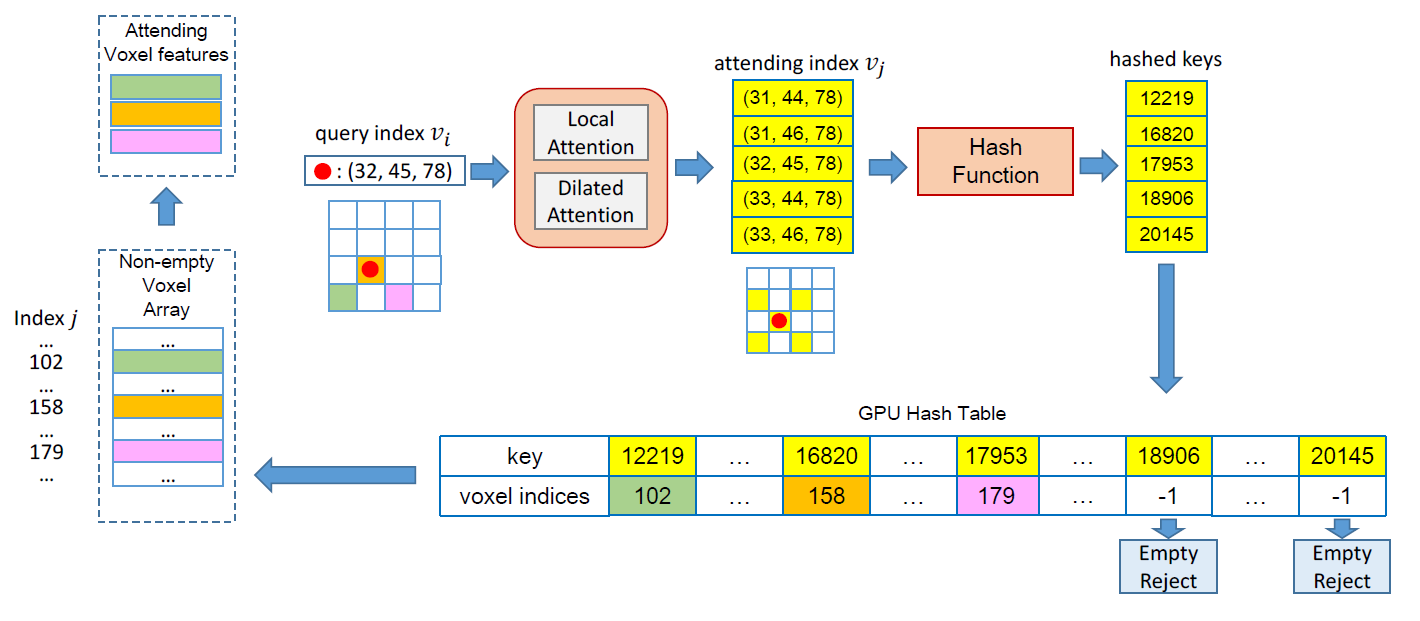
Voxel Transformer for 3D Object Detection
Jiageng Mao*, Yujing Xue*, Minzhe Niu, Haoyue Bai, Jiashi Feng, Xiaodan Liang, Hang Xu, Chunjing
Xu.
International Conference on Computer Vision (ICCV), 2021.
★ Covered at Stanford CS348n. ★
Course
Link •
Code

Interpolated Convolutional Networks for 3D Point Cloud Understanding
Jiageng Mao, Xiaogang Wang, Hongsheng Li.
International Conference on Computer Vision (ICCV), 2019.
★ Oral presentation (Top 4%). ★
Interpolated Convolutional Networks for 3D Point Cloud Understanding
Jiageng Mao, Xiaogang Wang, Hongsheng Li.
International Conference on Computer Vision (ICCV), 2019.
★ Oral presentation (Top 4%). ★
2026
Nanyang Technological University2026
Stanford University (Host: Prof. Gordon Wetzstein's Lab)2026
Peking University2025
Google DeepMind2025
Stanford University (Host: Prof. Leo Guibas's Lab)2025
ICRA 2025 Oral Presentation: DreamDrive: Generative 4D Scene Modeling from Street View Images2025
Stanford University (Host: MSL Lab)2025
Carnegie Mellon University (Host: Prof. Ding Zhao's Group)2024
Qualcomm2023
Cornell University (Host: Prof. Kilian Weinberger's Group)Here are some (not all) students I have worked with:
2025
CSCI-677 Robot Perception.2024
CSCI-670 Advanced Computer Vision.2021
ENGR-597 Signals and Systems.2020
ENGR-197 Multivariable Calculus.including CVPR, ICCV, ECCV, IJCV, T-PAMI, ICRA, IROS, CoRL, T-RO, NeurIPS, ICML, ICLR, etc.